CSVファイルの株価データをデーターベースへ
データーベースから取り出した株価をJupyter Notebookで分析したくなったのでCSVファイルの株価をデーターベースに入れる処理を書いてみた。
テーブル定義
MariaDBを使う、超ええかげんの設計。問題があればその時に直す。元データがあるのでなんとかなるだろう。
| |
株価をCSVファイルからデーターベースに格納する
株価データは http://k-db.com/ からダウンロードしてきたCSVファイルをデーターベースに入れる。
| |
データーベースに入れる処理はここまでで出来る。
データーベースから株価を取り出す
データーベースの株価(日足)はこんなふうに取り出す。
| |
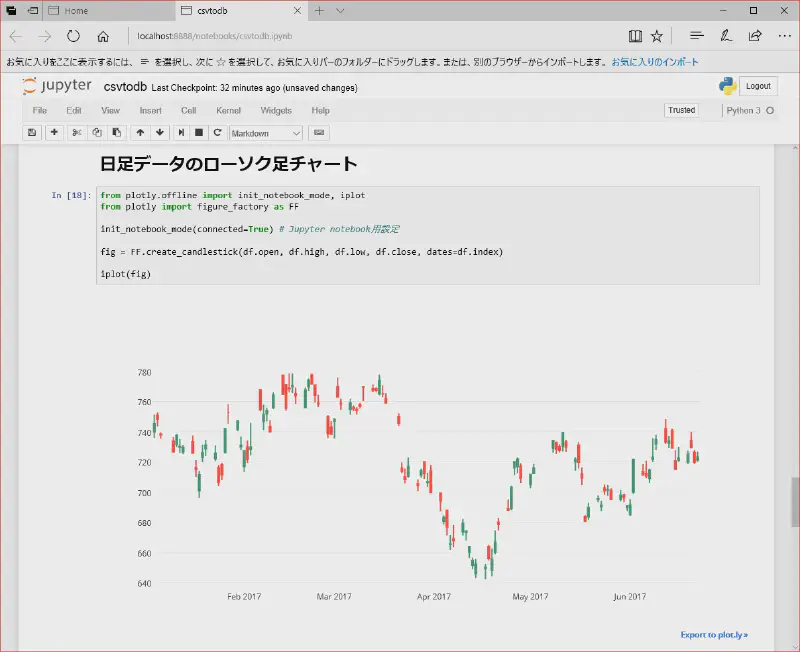
ローソク足チャート
Pythonでローソク足チャートの表示(Plotly編) を参考に日足データのローソク足チャートを表示
| |
実行するとこう
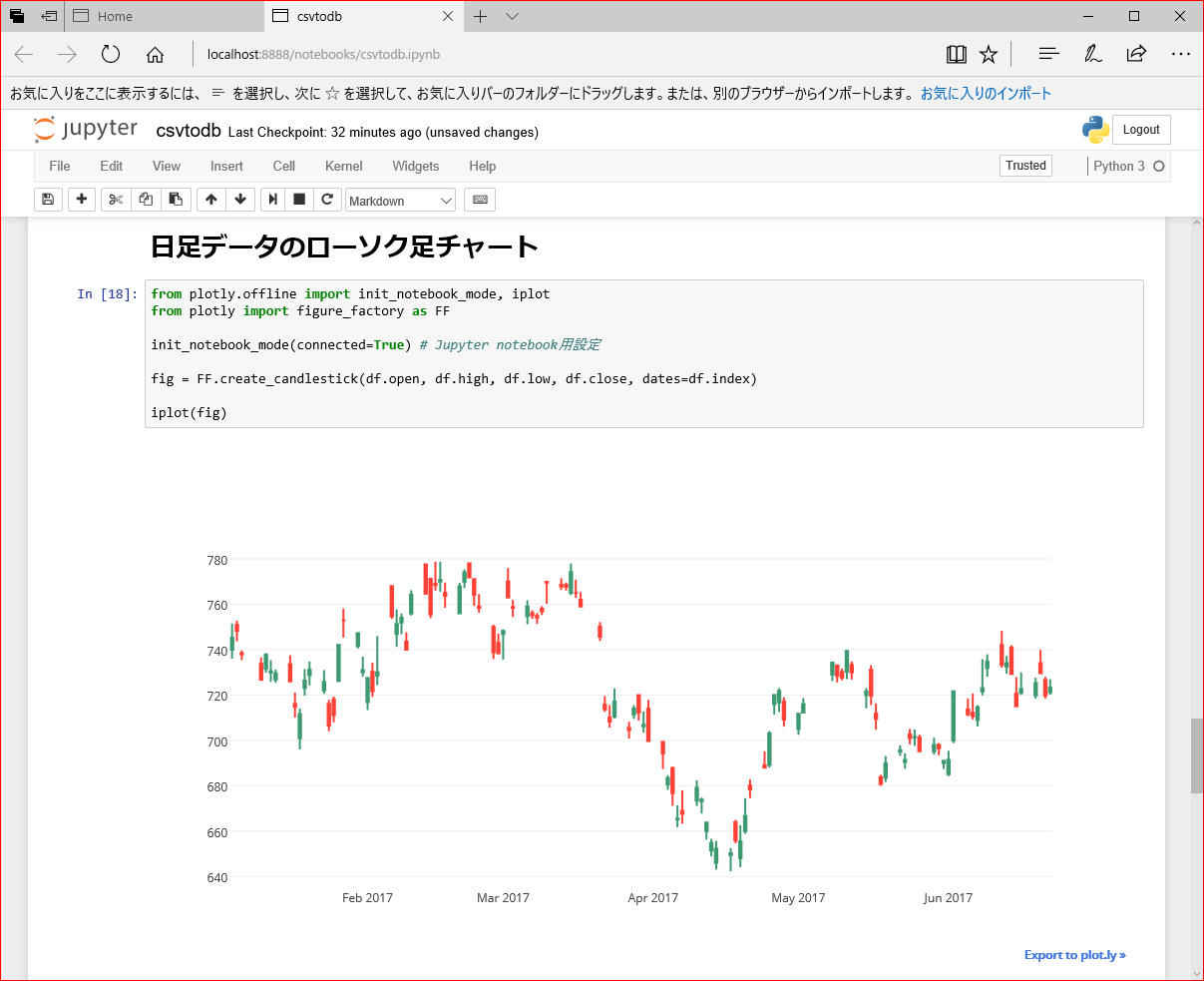
いろいろ気になる所があるけど、いじるのはまた今度。
使い方はこのipynbを見てね
HaskellでCSVファイルの株価データをデーターベースに入れてみた。
前回PythonでCSVファイルの株価データをデーターベースに入れるスクリプトを作った。
データーベースに株価を入れて、Pandasでテクニカル分析を始めるのはちょっとおいといて、Haskellで書きたい気分だったのでポーティングしてみた。 結果が同じプログラムを二つ持っても無意味だけど、Pythonで書いたものとHaskellで書いたものをGitHUBにおいておきます。
ではPythonでCSVファイルの株価データをデーターベースに入れて、ローソク足チャートを描いてみた。のコピペから始めます。
テーブル定義
MariaDBを使う。
| |
株価をCSVファイルからデーターベースに格納する
株価データは http://k-db.com/ からダウンロードしてきたCSVファイルをデーターベースに入れる。
入力はこんなCSVファイルを想定しています。
1時間足CSVの場合
| |
日足CSVの場合
| |
1時間足CSVは8列で日足CSVは7列であることに注意することと、日本語の取り扱いは面倒なので1行目は読み飛ばしてパースします。
CSVファイルをパースして株価を得る
Pythonではpandas.read_csvにheader=None, skiprows=1の指定でCSVファイルをパースします。
| |
Haskellにpandas.read_csvは無かったので自分で作ったCSVファイルパーサーでCSVファイルを読んでパースします。
| |
Real World Haskell 16章のCSVパーサー をカスタマイズした物です。
この部分は時刻列は有るかもしれないし、無いかもしれないと宣言しています。
| |
この部分で7列または8列のCSVしか受け付けないとパターンマッチで表現してます。
| |
株価CSVファイルを読み込む処理は以上で終わり。
株価CSVの行をテーブルの定義に合わせて変換してデーターベースへ
Pythonでは pandas.read_csv を使ったので、
返値は pandas.DataFrame になっている。
それにcombine_date_time関数を DataFrameに適用 して
変換後に pandas.DataFrame.to_sql でデーターベースに入れる。
| |
| |
こういう物を見たら部分適用していると思ってください。
Haskellにpandas.DataFrameは無かったので、 自分で作ったparseStocksCSVFile関数の返値のRight StocksCSVにこの関数(基準時間は日本時間なのでdatetimeに変換するときに+0900を入れておく)を 関数適用して変換後executeInsertIgnoreDB関数でデーターベースに入れる。 (Leftはパースエラーだからprint関数が適用される。)
| |
MariaDBにアクセス
Haskellで実装された MySQL ドライバ mysql-haskell を試してみた - qiitaを参考にして書いた。 こことかコピペしました、ありがとうございました。 O/Rマッパ(的な何か)が無いので、適当にDBアクセサの型クラスを用意した。 それぞれ Tohlc型をclass DataBaseAccessibleのインスタンスにする所と Textra型をclass DataBaseAccessibleのインスタンスにする所です。
正直mysql-haskellがよく分かってないので説明は無しの方向で。
以上で株価をCSVファイルからデーターベースに格納できた。
株価を集計する
バッチ処理として、1時間足テーブルから株価を取り出して集計し、日足テーブルに入れる。
Pythonではこの関数で行なう。
| |
集計処理は pandas.DataFrame.resample に pandas.core.resample.Resampler.aggregate を組み合わせて集計する。
| |
引数に集計方法を渡して呼ぶ。
‘open’は初期値, ‘high’は最大値, ’low’は最安値, ‘close’は最終値 つまり4本値の集計法。 ‘volume’は総和, ’turnover’は総和とした。
Haskellではこのようにバッチ処理関数の引数に具体的な集計関数を渡して行なう。
| |
| |
Haskellにpandas.core.resample.Resampler.aggregateは無かったので、集計用の高階関数に
| |
具体的な集計関数を渡して集計する。
| |
aggregateOHLCでは初値-終値の時系列リストで初値中の初値、高値中の最高値、安値中の最安値、終値中の終値を集計する。取引が行なわれないことがあるので(期間中に売買が無いとかストップ高/安、取引停止など)、これは欠損値(N/A)を許容する。 aggregateExtraでは出来高の総和, 売買代金の総和を集計する。 ここで、空リストが渡されるのはグループ化に失敗しているので、Nothingを返す。
ついでに、上でこんなふうに書かれているとおり(一部省略)に
| |
この高階関数に渡す集計関数は型クラスDataBaseAccessibleと型クラスDailyAggregatable両方のインスタンスでないとエラーになる。当然これらは
| |
Tohlcは DataBaseAccessibleのインスタンスでDailyAggregatableのインスタンス Textraは DataBaseAccessibleのインスタンスでDailyAggregatableのインスタンス となっているので集計関数として渡せる。
コマンドラインプログラムにする
PythonはJupyter notebookで実行したので不要だけど、このHaskell版はコマンドラインプログラムにするので、 Haskellでコマンドラインアプリケーションを作る時の基本的な情報とTips を参考にした。ありがとうございました。
csvtodbコマンドのソースファイルはMainCsvToDB.hs
batchdbコマンドのソースファイルはMainBatchDB.hs
コンパイル&インストール
| |
テスト
テストなのでmysqlコマンドでテーブルを消してから
| |
普通の株価データの場合(8306-T)
| |
とすると
| |
この入力ファイルからこのように
| |
データーベースに入る。続いて
| |
とすると
| |
1時間足テーブルを集計して日足テーブルに入る。きちんとダウンロードしてきた日足CSVと一致する。
| |
欠損値のある株価データの場合(7312-T)
| |
とすると
| |
この入力ファイルからこのように
| |
取引のなかった時間帯にはNULLが入っている。続いて
| |
とすると
| |
1時間足テーブルを集計して日足テーブルに入る。欠損値も含めてダウンロードしてきた日足CSVと一致する。
| |
Python版も結果は同じ。というかオリジナル。ここまででPythonからHaskellに移植できた。