CSVファイルの株価データをデーターベースへ
データーベースから取り出した株価をJupyter Notebookで分析したくなったのでCSVファイルの株価をデーターベースに入れる処理を書いてみた。
テーブル定義
MariaDBを使う、超ええかげんの設計。問題があればその時に直す。元データがあるのでなんとかなるだろう。
# 始値,高値,安値,終値(1時間足)
CREATE TABLE `ohlc_1h` (
`id` BIGINT(20) UNSIGNED NOT NULL,
`sec_code` SMALLINT(5) UNSIGNED NOT NULL,
`at` DATETIME NOT NULL,
`open` FLOAT NULL DEFAULT NULL,
`high` FLOAT NULL DEFAULT NULL,
`low` FLOAT NULL DEFAULT NULL,
`close` FLOAT NULL DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
# 出来高,売買代金(1時間足)
CREATE TABLE `extra_1h` (
`id` BIGINT(20) UNSIGNED NOT NULL,
`sec_code` SMALLINT(5) UNSIGNED NOT NULL,
`at` DATETIME NOT NULL,
`volume` BIGINT(20) UNSIGNED NULL DEFAULT NULL,
`turnover` BIGINT(20) UNSIGNED NULL DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
# 始値,高値,安値,終値(1日足)
CREATE TABLE `ohlc_1d` (
`id` BIGINT(20) UNSIGNED NOT NULL,
`sec_code` SMALLINT(5) UNSIGNED NOT NULL,
`at` DATE NOT NULL,
`open` FLOAT NULL DEFAULT NULL,
`high` FLOAT NULL DEFAULT NULL,
`low` FLOAT NULL DEFAULT NULL,
`close` FLOAT NULL DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
# 出来高,売買代金(1日足)
CREATE TABLE `extra_1d` (
`id` BIGINT(20) UNSIGNED NOT NULL,
`sec_code` SMALLINT(5) UNSIGNED NOT NULL,
`at` DATE NOT NULL,
`volume` BIGINT(20) UNSIGNED NULL DEFAULT NULL,
`turnover` BIGINT(20) UNSIGNED NULL DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;株価をCSVファイルからデーターベースに格納する
株価データは http://k-db.com/ からダウンロードしてきたCSVファイルをデーターベースに入れる。
import datetime
import numpy as np
import pandas as pd
from sqlalchemy import create_engine
from sqlalchemy.sql import text
# 証券コードと日付時刻から主キーを生成する関数
def make_ID(sec_code, datetime):
return 10**13 * sec_code + int(datetime.timestamp())
# CSVファイルの1レコードに主キーと証券コードを追加する関数
def append_key(sec_code, row):
datetime = pd.to_datetime (row['at'])
row['id'] = make_ID (sec_code, datetime)
row['sec_code'] = sec_code
return row
# CSVファイルを読み取ってデーターベースのテーブルに格納する関数
def csv_to_DB(engine, sec_code, tnames, csvfilename):
# CSVファイルの1行目は列名なので無視して
# 無視した列名の代わりを与える
df_csv = pd.read_csv (csvfilename, na_values='', header=None, skiprows=1)
if len(df_csv.columns) == 7:
df_csv.columns = ['date','open','high','low','close','volume','turnover']
else:
df_csv.columns = ['date','time','open','high','low','close','volume','turnover']
# date, time列を統合してat列を作る関数
def combine_date_time(row):
date_and_time = row['date']
del row['date']
if 'time' in row:
date_and_time = date_and_time + " " + row['time']
del row['time']
datetime = pd.to_datetime (date_and_time)
row['at'] = str(datetime)
return row
df = df_csv.apply (combine_date_time, axis=1)
df = df.apply (lambda r:append_key(sec_code,r), axis=1)
# 4値(ohlc)とその他に分ける
df_ohlc = df.loc[:,['id', 'sec_code', 'at', 'open', 'high', 'low', 'close']]
df_extra = df.loc[:,['id', 'sec_code', 'at', 'volume', 'turnover']]
# 分けた物をそれぞれのテーブルへ格納する
df_ohlc.to_sql (tnames['ohlc'], engine, if_exists='append', index=False)
df_extra.to_sql (tnames['extra'], engine, if_exists='append', index=False)
return df_csv
# 1時間足を日足へ変換してDBへ
def batch_resample_1day(engine, sec_code, tname_hourly, tname_daily, strategy):
# 日足テーブルに登録されている最後の日を得る
sql="SELECT MAX(at) AS 'latest' FROM `{}`".format (tname_daily)
sql=sql+" WHERE `sec_code`='{}'".format (sec_code)
sql=sql+";"
with engine.connect() as conn:
r = conn.execute(sql).fetchall()
latest = r[0].latest
# 日足テーブルに無いデーターを1時間足から計算して日足テーブルへ
sql="SELECT at,{} FROM `{}`".format (",".join(strategy.keys()), tname_hourly)
sql=sql+" WHERE `sec_code`='{}'".format (sec_code)
if latest:
nextday = latest + datetime.timedelta(days=1)
sql=sql+" AND `at` > '{}'".format (nextday.strftime('%Y-%m-%d'))
sql=sql+";"
df = pd.read_sql(sql, engine, index_col='at')
if not df.empty:
df = df.resample('1D').agg(strategy)
df = df.reset_index().apply (lambda x:append_key(sec_code,x), axis=1)
df.to_sql (tname_daily, engine, if_exists='append', index=False)データーベースに入れる処理はここまでで出来る。
データーベースから株価を取り出す
データーベースの株価(日足)はこんなふうに取り出す。
sql="SELECT at,open,high,low,close"
sql=sql+" FROM `{}`".format('ohlc_1d')
sql=sql+" WHERE `sec_code`='{}'".format(8306)
sql=sql+" AND `at` BETWEEN '{}' AND '{}'".format('2017-01-01','2017-12-31')
sql=sql+";"
df = pd.read_sql(sql, engine,index_col='at')ローソク足チャート
Pythonでローソク足チャートの表示(Plotly編) を参考に日足データのローソク足チャートを表示
from plotly.offline import init_notebook_mode, iplot
from plotly import figure_factory as FF
init_notebook_mode(connected=True) # Jupyter notebook用設定
fig = FF.create_candlestick(df.open, df.high, df.low, df.close, dates=df.index)
iplot(fig)実行するとこう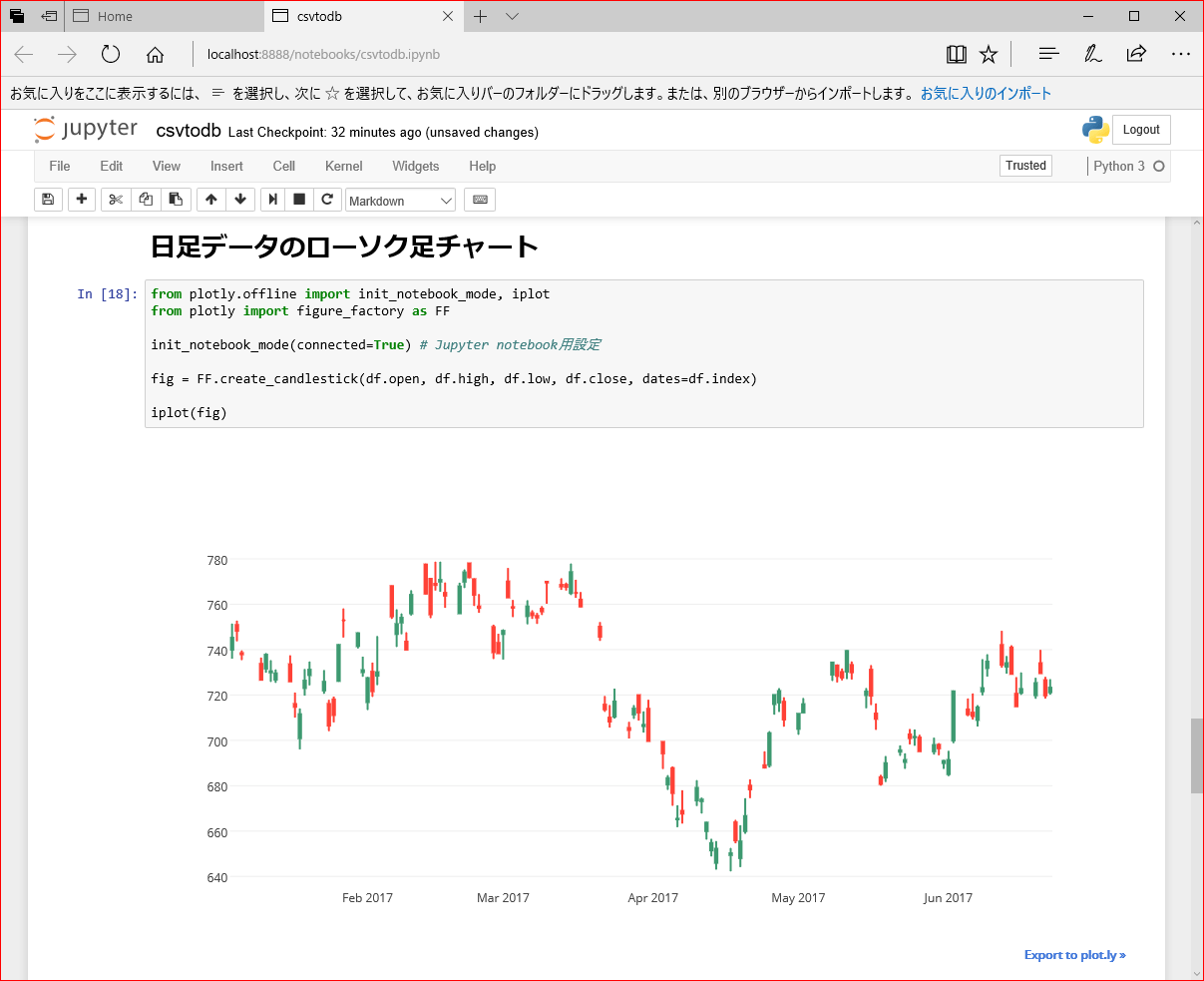
いろいろ気になる所があるけど、いじるのはまた今度。
使い方はこのipynbを見てね
HaskellでCSVファイルの株価データをデーターベースに入れてみた。
前回PythonでCSVファイルの株価データをデーターベースに入れるスクリプトを作った。
データーベースに株価を入れて、Pandasでテクニカル分析を始めるのはちょっとおいといて、Haskellで書きたい気分だったのでポーティングしてみた。 結果が同じプログラムを二つ持っても無意味だけど、Pythonで書いたものとHaskellで書いたものをGitHUBにおいておきます。
ではPythonでCSVファイルの株価データをデーターベースに入れて、ローソク足チャートを描いてみた。のコピペから始めます。
テーブル定義
MariaDBを使う。
# 始値,高値,安値,終値(1時間足)
CREATE TABLE `ohlc_1h` (
`id` BIGINT(20) UNSIGNED NOT NULL,
`sec_code` SMALLINT(5) UNSIGNED NOT NULL,
`at` DATETIME NOT NULL,
`open` FLOAT NULL DEFAULT NULL,
`high` FLOAT NULL DEFAULT NULL,
`low` FLOAT NULL DEFAULT NULL,
`close` FLOAT NULL DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
# 出来高,売買代金(1時間足)
CREATE TABLE `extra_1h` (
`id` BIGINT(20) UNSIGNED NOT NULL,
`sec_code` SMALLINT(5) UNSIGNED NOT NULL,
`at` DATETIME NOT NULL,
`volume` BIGINT(20) UNSIGNED NULL DEFAULT NULL,
`turnover` BIGINT(20) UNSIGNED NULL DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
# 始値,高値,安値,終値(1日足)
CREATE TABLE `ohlc_1d` (
`id` BIGINT(20) UNSIGNED NOT NULL,
`sec_code` SMALLINT(5) UNSIGNED NOT NULL,
`at` DATE NOT NULL,
`open` FLOAT NULL DEFAULT NULL,
`high` FLOAT NULL DEFAULT NULL,
`low` FLOAT NULL DEFAULT NULL,
`close` FLOAT NULL DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
# 出来高,売買代金(1日足)
CREATE TABLE `extra_1d` (
`id` BIGINT(20) UNSIGNED NOT NULL,
`sec_code` SMALLINT(5) UNSIGNED NOT NULL,
`at` DATE NOT NULL,
`volume` BIGINT(20) UNSIGNED NULL DEFAULT NULL,
`turnover` BIGINT(20) UNSIGNED NULL DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;株価をCSVファイルからデーターベースに格納する
株価データは http://k-db.com/ からダウンロードしてきたCSVファイルをデーターベースに入れる。
入力はこんなCSVファイルを想定しています。
1時間足CSVの場合
日付,時刻,始値,高値,安値,終値,出来高,売買代金
2017-06-22,15:00,723.20,723.20,723.20,723.20,4715700,3410394240
2017-06-22,14:00,724.10,724.50,722.70,723.30,8502700,6153392440
2017-06-22,13:00,725.20,725.90,723.80,724.20,6541300,4740525080
2017-06-22,12:00,724.60,726.30,724.50,725.10,5097200,3697410600
2017-06-22,11:00,726.10,727.00,724.20,724.70,4436700,3219408850
2017-06-22,10:00,724.30,726.10,724.10,726.00,7653800,5551692260
2017-06-22,09:00,721.20,726.80,720.10,724.30,14817600,10722071400
2017-06-21,15:00,719.80,719.80,719.80,719.80,6541200,4708355760
2017-06-21,14:00,721.00,722.50,719.50,719.60,10962200,7900242650
2017-06-21,13:00,719.60,722.00,719.50,721.00,7625500,5494562800
2017-06-21,12:00,719.60,720.20,718.40,719.60,5547700,3989569240
2017-06-21,11:00,720.80,721.00,719.30,719.80,3454100,2487052880
2017-06-21,10:00,722.60,723.90,719.70,720.80,8986600,6483836650
2017-06-21,09:00,726.50,728.00,720.00,722.60,17052700,12328551350
2017-06-20,15:00,729.60,729.60,729.60,729.60,8369800,6106606080
2017-06-20,14:00,733.20,734.20,729.60,729.60,11288700,8263003850
2017-06-20,13:00,735.70,735.80,732.40,733.30,6599600,4843813720
2017-06-20,12:00,736.60,736.60,734.20,735.60,4715100,3468436690
2017-06-20,11:00,736.10,736.30,735.10,735.40,3166700,2329844210
2017-06-20,10:00,737.20,738.30,735.50,736.10,7070000,5209238710
2017-06-20,09:00,734.00,739.90,733.80,737.20,23773600,17509326730日足CSVの場合
日付,始値,高値,安値,終値,出来高,売買代金
2017-06-21,726.50,728.00,718.40,719.80,60170000,43392171330
2017-06-20,734.00,739.90,729.60,729.60,64983500,47730269990
2017-06-19,719.90,727.60,718.30,725.20,42098400,30474304170
2017-06-16,721.00,730.00,720.00,722.60,104013700,75347866130
2017-06-15,720.50,727.90,715.00,715.00,72207900,51958158180
2017-06-14,740.90,741.90,729.30,729.30,56718700,41660042300
2017-06-13,732.50,737.20,729.40,734.00,40896300,30022093510
2017-06-12,742.00,748.30,732.00,733.30,69324400,51295336450
2017-06-09,731.90,738.00,728.10,734.70,118601100,869624205001時間足CSVは8列で日足CSVは7列であることに注意することと、日本語の取り扱いは面倒なので1行目は読み飛ばしてパースします。
CSVファイルをパースして株価を得る
Pythonではpandas.read_csvにheader=None, skiprows=1の指定でCSVファイルをパースします。
# CSVファイルの1行目は列名なので無視して
# 無視した列名の代わりを与える
df_csv = pd.read_csv (csvfilename, na_values='', header=None, skiprows=1)
if len(df_csv.columns) == 7:
df_csv.columns = ['date','open','high','low','close','volume','turnover']
else:
df_csv.columns = ['date','time','open','high','low','close','volume','turnover']Haskellにpandas.read_csvは無かったので自分で作ったCSVファイルパーサーでCSVファイルを読んでパースします。
-- | CSV行の定義
data CSVRow = CSVRow
{ rDate :: BL8.ByteString
, rTime :: Maybe BL8.ByteString
, rOpen :: BL8.ByteString
, rHigh :: BL8.ByteString
, rLow :: BL8.ByteString
, rClose :: BL8.ByteString
, rVolume :: BL8.ByteString
, rTurnover :: BL8.ByteString
} deriving Show
-- | CSV行のリスト = 株価CSVファイル
type StocksCSV = [CSVRow]
-- | CSVファイルパーサー
parseStocksCSVFile :: String -> IO (Either P.ParseError StocksCSV)
parseStocksCSVFile fileName =
liftM toStocksCSV <$> P.parseFromFile csvFile fileName
where
--
toRow :: [BL8.ByteString] -> CSVRow
toRow [a,b,c,d,e,f,g] = CSVRow a Nothing b c d e f g
toRow [a,b,c,d,e,f,g,h] = CSVRow a (Just b) c d e f g h
toRow _ = error "Unsupported CSV file."
--
toStocksCSV :: [[String]] -> StocksCSV
toStocksCSV = map (toRow . map BL8.pack)
--
csvFile = line *> eol -- 1行目のタイトル行は不要なので読み捨てる
*> P.endBy line eol -- 株価は2行目から
--
line = P.sepBy cell (P.char ',')
--
cell = P.many (P.noneOf ",\n\r")
--
eol = P.try (P.string "\n\r")
<|> P.try (P.string "\r\n")
<|> P.string "\n"
<|> P.string "\r"
<?> "end of line"Real World Haskell 16章のCSVパーサー をカスタマイズした物です。
この部分は時刻列は有るかもしれないし、無いかもしれないと宣言しています。
, cTime :: Maybe BL8.ByteStringこの部分で7列または8列のCSVしか受け付けないとパターンマッチで表現してます。
toRow [a,b,c,d,e,f,g] = CSVRow a Nothing b c d e f g
toRow [a,b,c,d,e,f,g,h] = CSVRow a (Just b) c d e f g h
toRow _ = error "Unsupported CSV file."株価CSVファイルを読み込む処理は以上で終わり。
株価CSVの行をテーブルの定義に合わせて変換してデーターベースへ
Pythonでは pandas.read_csv を使ったので、
返値は pandas.DataFrame になっている。
それにcombine_date_time関数を DataFrameに適用 して
変換後に pandas.DataFrame.to_sql でデーターベースに入れる。
# date, time列を統合してat列を作る関数
def combine_date_time(row):
date_and_time = row['date']
del row['date']
if 'time' in row:
date_and_time = date_and_time + " " + row['time']
del row['time']
datetime = pd.to_datetime (date_and_time)
row['at'] = str(datetime)
return row
df = df_csv.apply (combine_date_time, axis=1)
df = df.apply (lambda r:append_key(sec_code,r), axis=1)
# 4値(ohlc)とその他に分ける
df_ohlc = df.loc[:,['id', 'sec_code', 'at', 'open', 'high', 'low', 'close']]
df_extra = df.loc[:,['id', 'sec_code', 'at', 'volume', 'turnover']]
# 分けた物をそれぞれのテーブルへ格納する
df_ohlc.to_sql (tnames['ohlc'], engine, if_exists='append', index=False)
df_extra.to_sql (tnames['extra'], engine, if_exists='append', index=False)
return df_csvlambda r:append_key(sec_code,r)こういう物を見たら部分適用していると思ってください。
Haskellにpandas.DataFrameは無かったので、 自分で作ったparseStocksCSVFile関数の返値のRight StocksCSVにこの関数(基準時間は日本時間なのでdatetimeに変換するときに+0900を入れておく)を 関数適用して変換後executeInsertIgnoreDB関数でデーターベースに入れる。 (Leftはパースエラーだからprint関数が適用される。)
stockDataToDB :: DB.MySQLConn -> Word16 -> (String,String) -> StocksCSV -> IO ()
stockDataToDB conn secCode (tnOhlc, tnExtra) rows = do
let (ohlcs, extras) = unzip (map separate rows)
executeInsertIgnoreDB conn tnOhlc ohlcs
executeInsertIgnoreDB conn tnExtra extras
-- CSV行からohlc, extraを作る
separate :: CSVRow -> (Tohlc, Textra)
separate (CSVRow date mTime open high low close volume turnover) =
let dateTime = parseTimeOrError True defaultTimeLocale
(iso8601DateFormat (Just "%H:%M:%S%z")) . BL8.unpack
$ BL8.concat [date, "T", fromMaybe "00:00" mTime, ":00+0900"]
in
let id = makeID secCode dateTime in
let at = utcToLocalTime jst dateTime in
let open' = Safe.readMay (BL8.unpack open) in
let high' = Safe.readMay (BL8.unpack high) in
let low' = Safe.readMay (BL8.unpack low) in
let close' = Safe.readMay (BL8.unpack close) in
let volume' = Safe.readNote "出来高の読み取りに失敗しました" (BL8.unpack volume) in
let turnover' = Safe.readNote "売買代金の読み取りに失敗しました" (BL8.unpack turnover) in
( Tohlc id secCode at open' high' low' close'
, Textra id secCode at volume' turnover')MariaDBにアクセス
Haskellで実装された MySQL ドライバ mysql-haskell を試してみた - qiitaを参考にして書いた。 こことかコピペしました、ありがとうございました。 O/Rマッパ(的な何か)が無いので、適当にDBアクセサの型クラスを用意した。 それぞれ Tohlc型をclass DataBaseAccessibleのインスタンスにする所と Textra型をclass DataBaseAccessibleのインスタンスにする所です。
正直mysql-haskellがよく分かってないので説明は無しの方向で。
以上で株価をCSVファイルからデーターベースに格納できた。
株価を集計する
バッチ処理として、1時間足テーブルから株価を取り出して集計し、日足テーブルに入れる。
Pythonではこの関数で行なう。
# 1時間足を日足へ変換してDBへ
def batch_resample_1day(engine, sec_code, tname_hourly, tname_daily, strategy):
# 日足テーブルに登録されている最後の日を得る
sql="SELECT MAX(at) AS 'latest' FROM `{}`".format (tname_daily)
sql=sql+" WHERE `sec_code`='{}'".format (sec_code)
sql=sql+";"
with engine.connect() as conn:
r = conn.execute(sql).fetchall()
latest = r[0].latest
# 日足テーブルに無いデーターを1時間足から計算して日足テーブルへ
sql="SELECT at,{} FROM `{}`".format (",".join(strategy.keys()), tname_hourly)
sql=sql+" WHERE `sec_code`='{}'".format (sec_code)
if latest:
nextday = latest + datetime.timedelta(days=1)
sql=sql+" AND `at` > '{}'".format (nextday.strftime('%Y-%m-%d'))
sql=sql+";"
df = pd.read_sql(sql, engine, index_col='at')
if not df.empty:
df = df.resample('1D').agg(strategy)
df = df.reset_index().apply (lambda x:append_key(sec_code,x), axis=1)
df.to_sql (tname_daily, engine, if_exists='append', index=False)集計処理は pandas.DataFrame.resample に pandas.core.resample.Resampler.aggregate を組み合わせて集計する。
batch_resample_1day(engine, 8306, 'ohlc_1h', 'ohlc_1d', {'open':'first', 'high':'max', 'low':'min', 'close':'last'})
batch_resample_1day(engine, 8306, 'extra_1h', 'extra_1d', {'volume':'sum', 'turnover':'sum'})引数に集計方法を渡して呼ぶ。
‘open’は初期値, ‘high’は最大値, ’low’は最安値, ‘close’は最終値 つまり4本値の集計法。 ‘volume’は総和, ’turnover’は総和とした。
Haskellではこのようにバッチ処理関数の引数に具体的な集計関数を渡して行なう。
batchResampleDaily conn secCode "ohlc_1h" "ohlc_1d" aggregateOHLC
batchResampleDaily conn secCode "extra_1h" "extra_1d" aggregateExtra-- | 立ち会い終了後のバッチ処理
batchResampleDaily :: (DataBaseAccessible a, DailyAggregatable a)
=> DB.MySQLConn -> Word16
-> String -> String
-> ([a] -> Maybe a)
-> IO ()
batchResampleDaily conn secCode tnHourly tnDaily methodOfAgg = do
-- 1時間足テーブルからのデータを集計して日足テーブルに追加する
dailies <- aggregate conn secCode tnHourly tnDaily methodOfAgg
executeInsertIgnoreDB conn tnDaily (catMaybes dailies)Haskellにpandas.core.resample.Resampler.aggregateは無かったので、集計用の高階関数に
-- | 集計関数
aggregate :: (DataBaseAccessible a, DailyAggregatable a)
=> DB.MySQLConn -> Word16
-> String -> String
-> ([a] -> Maybe a)
-> IO [Maybe a]
aggregate conn secCode tnHourly tnDaily methodOfAgg = do
-- 日足テーブルに入っているデータの最終日を得て
latest <- latestDayInTable conn tnDaily secCode
-- その翌営業日以降のデータを1時間足テーブルから取り出す
hourlies <- selectQueryDB conn tnHourly secCode (nextDay <$> latest)
-- 日ごとにグループ化してグループごとに集計
let dailyGroups = List.groupBy isSameDay hourlies
let dailies = map (fmap atMidnight . methodOfAgg) dailyGroups
return dailies
where
--
nextDay :: Day -> BL8.ByteString
nextDay day =
let n = addDays 1 day in
BL8.concat ["AND `at` >= '",BL8.pack (show n), "' "]具体的な集計関数を渡して集計する。
-- | 始値, 高値, 安値, 終値を集計する関数
aggregateOHLC :: [Tohlc] -- ^ 初値-終値の時系列通りで与えること
-> Maybe Tohlc
aggregateOHLC xs =
case Safe.headMay (reverse xs) of
Nothing -> Nothing -- 空リストのOHLCは未定義
Just last -> Just $
-- 4本値は欠損値を許容する
let open = Safe.headMay $ mapMaybe ohlcOpen xs in -- 集計期間中の初値
let high = Safe.maximumMay $ mapMaybe ohlcHigh xs in -- 集計期間中の最高値
let low = Safe.minimumMay $ mapMaybe ohlcLow xs in -- 集計期間中の最安値
let close = Safe.headMay $ mapMaybe ohlcClose (reverse xs) in -- 集計期間中の終値
last { ohlcOpen = open
, ohlcHigh = high
, ohlcLow = low
, ohlcClose = close
}
-- | 出来高, 売買代金を集計する関数
aggregateExtra :: [Textra] -> Maybe Textra
aggregateExtra xs =
case Safe.headMay (reverse xs) of
Nothing -> Nothing -- 空リストの出来高,売買代金は未定義
Just last -> Just $
last { extraVolume = sum (map extraVolume xs) -- 集計期間中の総和
, extraTurnover = sum (map extraTurnover xs) -- 集計期間中の総和
}aggregateOHLCでは初値-終値の時系列リストで初値中の初値、高値中の最高値、安値中の最安値、終値中の終値を集計する。取引が行なわれないことがあるので(期間中に売買が無いとかストップ高/安、取引停止など)、これは欠損値(N/A)を許容する。 aggregateExtraでは出来高の総和, 売買代金の総和を集計する。 ここで、空リストが渡されるのはグループ化に失敗しているので、Nothingを返す。
ついでに、上でこんなふうに書かれているとおり(一部省略)に
batchResampleDaily :: (DataBaseAccessible a, DailyAggregatable a)
=> ([a] -> Maybe a)この高階関数に渡す集計関数は型クラスDataBaseAccessibleと型クラスDailyAggregatable両方のインスタンスでないとエラーになる。当然これらは
aggregateOHLC :: [Tohlc] -> Maybe Tohlc
aggregateExtra :: [Textra] -> Maybe TextraTohlcは DataBaseAccessibleのインスタンスでDailyAggregatableのインスタンス Textraは DataBaseAccessibleのインスタンスでDailyAggregatableのインスタンス となっているので集計関数として渡せる。
コマンドラインプログラムにする
PythonはJupyter notebookで実行したので不要だけど、このHaskell版はコマンドラインプログラムにするので、 Haskellでコマンドラインアプリケーションを作る時の基本的な情報とTips を参考にした。ありがとうございました。
csvtodbコマンドのソースファイルはMainCsvToDB.hs
batchdbコマンドのソースファイルはMainBatchDB.hs
コンパイル&インストール
stack installテスト
テストなのでmysqlコマンドでテーブルを消してから
MariaDB [stockdb]> delete from ohlc_1h where sec_code=8306;
Query OK, 0 rows affected (0.00 sec)
MariaDB [stockdb]> delete from ohlc_1d where sec_code=8306;
Query OK, 0 rows affected (0.01 sec)
MariaDB [stockdb]> delete from extra_1h where sec_code=8306;
Query OK, 0 rows affected (0.00 sec)
MariaDB [stockdb]> delete from extra_1d where sec_code=8306;
Query OK, 0 rows affected (0.00 sec)普通の株価データの場合(8306-T)
csvtodb -uUSERNAMEHERE -pPASSWORDHERE 8306 1h ~/stocks_8306-T_1h_201703.csvとすると
日付,時刻,始値,高値,安値,終値,出来高,売買代金
2017-03-31,15:00,699.70,699.70,699.70,699.70,13319700,9319794090
2017-03-31,14:00,708.10,708.50,700.20,700.20,17270400,12174721130
2017-03-31,13:00,714.20,714.40,707.60,708.00,8028200,5708604540
2017-03-31,12:00,713.60,715.50,713.00,714.20,4142000,2959390410
2017-03-31,11:00,712.10,714.70,712.00,713.40,2258700,1611634080
2017-03-31,10:00,714.80,714.90,711.30,712.10,5404400,3853464160
2017-03-31,09:00,713.90,717.90,712.60,714.80,15576600,11140877960この入力ファイルからこのように
MariaDB [stockdb]> SELECT * FROM `ohlc_1h` WHERE `sec_code`='8306' ORDER BY `at` DESC LIMIT 7;
+-------------------+----------+---------------------+-------+-------+-------+-------+
| id | sec_code | at | open | high | low | close |
+-------------------+----------+---------------------+-------+-------+-------+-------+
| 83060001490940000 | 8306 | 2017-03-31 15:00:00 | 699.7 | 699.7 | 699.7 | 699.7 |
| 83060001490936400 | 8306 | 2017-03-31 14:00:00 | 708.1 | 708.5 | 700.2 | 700.2 |
| 83060001490932800 | 8306 | 2017-03-31 13:00:00 | 714.2 | 714.4 | 707.6 | 708 |
| 83060001490929200 | 8306 | 2017-03-31 12:00:00 | 713.6 | 715.5 | 713 | 714.2 |
| 83060001490925600 | 8306 | 2017-03-31 11:00:00 | 712.1 | 714.7 | 712 | 713.4 |
| 83060001490922000 | 8306 | 2017-03-31 10:00:00 | 714.8 | 714.9 | 711.3 | 712.1 |
| 83060001490918400 | 8306 | 2017-03-31 09:00:00 | 713.9 | 717.9 | 712.6 | 714.8 |
+-------------------+----------+---------------------+-------+-------+-------+-------+
7 rows in set (0.00 sec)
MariaDB [stockdb]> SELECT * FROM `extra_1h` WHERE `sec_code`='8306' ORDER BY `at` DESC LIMIT 7;
+-------------------+----------+---------------------+----------+-------------+
| id | sec_code | at | volume | turnover |
+-------------------+----------+---------------------+----------+-------------+
| 83060001490940000 | 8306 | 2017-03-31 15:00:00 | 13319700 | 9319794090 |
| 83060001490936400 | 8306 | 2017-03-31 14:00:00 | 17270400 | 12174721130 |
| 83060001490932800 | 8306 | 2017-03-31 13:00:00 | 8028200 | 5708604540 |
| 83060001490929200 | 8306 | 2017-03-31 12:00:00 | 4142000 | 2959390410 |
| 83060001490925600 | 8306 | 2017-03-31 11:00:00 | 2258700 | 1611634080 |
| 83060001490922000 | 8306 | 2017-03-31 10:00:00 | 5404400 | 3853464160 |
| 83060001490918400 | 8306 | 2017-03-31 09:00:00 | 15576600 | 11140877960 |
+-------------------+----------+---------------------+----------+-------------+
7 rows in set (0.00 sec)データーベースに入る。続いて
batchdb -uUSERNAMEHERE -pPASSWORDHERE 8306とすると
MariaDB [stockdb]> SELECT * FROM `ohlc_1d` WHERE `sec_code`='8306' ORDER BY `at` DESC LIMIT 7;
+-------------------+----------+------------+-------+-------+-------+-------+
| id | sec_code | at | open | high | low | close |
+-------------------+----------+------------+-------+-------+-------+-------+
| 83060001490886000 | 8306 | 2017-03-31 | 713.9 | 717.9 | 699.7 | 699.7 |
| 83060001490799600 | 8306 | 2017-03-30 | 706.3 | 712.8 | 703.4 | 706.8 |
| 83060001490713200 | 8306 | 2017-03-29 | 719.9 | 719.9 | 708.7 | 712.3 |
| 83060001490626800 | 8306 | 2017-03-28 | 711.5 | 715.6 | 709.4 | 713.9 |
| 83060001490540400 | 8306 | 2017-03-27 | 705.4 | 708.2 | 700.8 | 704.6 |
| 83060001490281200 | 8306 | 2017-03-24 | 710.5 | 722.8 | 709.6 | 717.1 |
| 83060001490194800 | 8306 | 2017-03-23 | 710 | 715.6 | 705.6 | 708.3 |
+-------------------+----------+------------+-------+-------+-------+-------+
7 rows in set (0.00 sec)
MariaDB [stockdb]> SELECT * FROM `extra_1d` WHERE `sec_code`='8306' ORDER BY `at` DESC LIMIT 7;
+-------------------+----------+------------+----------+-------------+
| id | sec_code | at | volume | turnover |
+-------------------+----------+------------+----------+-------------+
| 83060001490886000 | 8306 | 2017-03-31 | 66000000 | 46768486370 |
| 83060001490799600 | 8306 | 2017-03-30 | 52173900 | 36942348360 |
| 83060001490713200 | 8306 | 2017-03-29 | 58357200 | 41582055360 |
| 83060001490626800 | 8306 | 2017-03-28 | 65068200 | 46389510590 |
| 83060001490540400 | 8306 | 2017-03-27 | 63944200 | 45006474510 |
| 83060001490281200 | 8306 | 2017-03-24 | 59189800 | 42465895790 |
| 83060001490194800 | 8306 | 2017-03-23 | 94270700 | 66851549540 |
+-------------------+----------+------------+----------+-------------+
7 rows in set (0.00 sec)1時間足テーブルを集計して日足テーブルに入る。きちんとダウンロードしてきた日足CSVと一致する。
日付,始値,高値,安値,終値,出来高,売買代金
2017-03-31,713.90,717.90,699.70,699.70,66000000,46768486370
2017-03-30,706.30,712.80,703.40,706.80,52173900,36942348360
2017-03-29,719.90,719.90,708.70,712.30,58357200,41582055360
2017-03-28,711.50,715.60,709.40,713.90,65068200,46389510590
2017-03-27,705.40,708.20,700.80,704.60,63944200,45006474510
2017-03-24,710.50,722.80,709.60,717.10,59189800,42465895790
2017-03-23,710.00,715.60,705.60,708.30,94270700,66851549540欠損値のある株価データの場合(7312-T)
csvtodb -uUSERNAMEHERE -pPASSWORDHERE 8306 1h ~/stocks_8306-T_1h_201703.csvとすると
日付,時刻,始値,高値,安値,終値,出来高,売買代金
2017-06-27,15:00,110.00,110.00,110.00,110.00,3459500,380545000
2017-06-27,14:00,,,,,0,0
2017-06-27,13:00,,,,,0,0
2017-06-27,12:00,,,,,0,0
2017-06-27,11:00,,,,,0,0
2017-06-27,10:00,,,,,0,0
2017-06-27,09:00,,,,,0,0
2017-06-26,15:00,,,,,0,0
2017-06-26,14:00,,,,,0,0
2017-06-26,13:00,,,,,0,0
2017-06-26,12:00,,,,,0,0
2017-06-26,11:00,,,,,0,0
2017-06-26,10:00,,,,,0,0
2017-06-26,09:00,,,,,0,0
2017-06-23,15:00,160.00,160.00,160.00,160.00,964100,154256000
2017-06-23,14:00,,,,,0,0
2017-06-23,13:00,,,,,0,0
2017-06-23,12:00,,,,,0,0
2017-06-23,11:00,160.00,160.00,159.00,160.00,621100,99363800
2017-06-23,10:00,154.00,160.00,152.00,160.00,5237000,823305400
2017-06-23,09:00,113.00,160.00,112.00,154.00,26151400,3604964200この入力ファイルからこのように
MariaDB [stockdb]> SELECT * FROM `ohlc_1h` WHERE `sec_code`='7312' AND '2017-6-23'<=`at` AND `at`<= '2017-6-28' ORDER BY `at` DESC; +-------------------+----------+---------------------+------+------+------+-------+
| id | sec_code | at | open | high | low | close |
+-------------------+----------+---------------------+------+------+------+-------+
| 73120001498543200 | 7312 | 2017-06-27 15:00:00 | 110 | 110 | 110 | 110 |
| 73120001498539600 | 7312 | 2017-06-27 14:00:00 | NULL | NULL | NULL | NULL |
| 73120001498536000 | 7312 | 2017-06-27 13:00:00 | NULL | NULL | NULL | NULL |
| 73120001498532400 | 7312 | 2017-06-27 12:00:00 | NULL | NULL | NULL | NULL |
| 73120001498528800 | 7312 | 2017-06-27 11:00:00 | NULL | NULL | NULL | NULL |
| 73120001498525200 | 7312 | 2017-06-27 10:00:00 | NULL | NULL | NULL | NULL |
| 73120001498521600 | 7312 | 2017-06-27 09:00:00 | NULL | NULL | NULL | NULL |
| 73120001498456800 | 7312 | 2017-06-26 15:00:00 | NULL | NULL | NULL | NULL |
| 73120001498453200 | 7312 | 2017-06-26 14:00:00 | NULL | NULL | NULL | NULL |
| 73120001498449600 | 7312 | 2017-06-26 13:00:00 | NULL | NULL | NULL | NULL |
| 73120001498446000 | 7312 | 2017-06-26 12:00:00 | NULL | NULL | NULL | NULL |
| 73120001498442400 | 7312 | 2017-06-26 11:00:00 | NULL | NULL | NULL | NULL |
| 73120001498438800 | 7312 | 2017-06-26 10:00:00 | NULL | NULL | NULL | NULL |
| 73120001498435200 | 7312 | 2017-06-26 09:00:00 | NULL | NULL | NULL | NULL |
| 73120001498197600 | 7312 | 2017-06-23 15:00:00 | 160 | 160 | 160 | 160 |
| 73120001498194000 | 7312 | 2017-06-23 14:00:00 | NULL | NULL | NULL | NULL |
| 73120001498190400 | 7312 | 2017-06-23 13:00:00 | NULL | NULL | NULL | NULL |
| 73120001498186800 | 7312 | 2017-06-23 12:00:00 | NULL | NULL | NULL | NULL |
| 73120001498183200 | 7312 | 2017-06-23 11:00:00 | 160 | 160 | 159 | 160 |
| 73120001498179600 | 7312 | 2017-06-23 10:00:00 | 154 | 160 | 152 | 160 |
| 73120001498176000 | 7312 | 2017-06-23 09:00:00 | 113 | 160 | 112 | 154 |
+-------------------+----------+---------------------+------+------+------+-------+
21 rows in set (0.01 sec)
MariaDB [stockdb]> SELECT * FROM `extra_1h` WHERE `sec_code`='7312' AND '2017-6-23'<=`at` AND `at`<= '2017-6-28' ORDER BY `at` DESC;
+-------------------+----------+---------------------+----------+------------+
| id | sec_code | at | volume | turnover |
+-------------------+----------+---------------------+----------+------------+
| 73120001498543200 | 7312 | 2017-06-27 15:00:00 | 3459500 | 380545000 |
| 73120001498539600 | 7312 | 2017-06-27 14:00:00 | 0 | 0 |
| 73120001498536000 | 7312 | 2017-06-27 13:00:00 | 0 | 0 |
| 73120001498532400 | 7312 | 2017-06-27 12:00:00 | 0 | 0 |
| 73120001498528800 | 7312 | 2017-06-27 11:00:00 | 0 | 0 |
| 73120001498525200 | 7312 | 2017-06-27 10:00:00 | 0 | 0 |
| 73120001498521600 | 7312 | 2017-06-27 09:00:00 | 0 | 0 |
| 73120001498456800 | 7312 | 2017-06-26 15:00:00 | 0 | 0 |
| 73120001498453200 | 7312 | 2017-06-26 14:00:00 | 0 | 0 |
| 73120001498449600 | 7312 | 2017-06-26 13:00:00 | 0 | 0 |
| 73120001498446000 | 7312 | 2017-06-26 12:00:00 | 0 | 0 |
| 73120001498442400 | 7312 | 2017-06-26 11:00:00 | 0 | 0 |
| 73120001498438800 | 7312 | 2017-06-26 10:00:00 | 0 | 0 |
| 73120001498435200 | 7312 | 2017-06-26 09:00:00 | 0 | 0 |
| 73120001498197600 | 7312 | 2017-06-23 15:00:00 | 964100 | 154256000 |
| 73120001498194000 | 7312 | 2017-06-23 14:00:00 | 0 | 0 |
| 73120001498190400 | 7312 | 2017-06-23 13:00:00 | 0 | 0 |
| 73120001498186800 | 7312 | 2017-06-23 12:00:00 | 0 | 0 |
| 73120001498183200 | 7312 | 2017-06-23 11:00:00 | 621100 | 99363800 |
| 73120001498179600 | 7312 | 2017-06-23 10:00:00 | 5237000 | 823305400 |
| 73120001498176000 | 7312 | 2017-06-23 09:00:00 | 26151400 | 3604964200 |
+-------------------+----------+---------------------+----------+------------+
21 rows in set (0.00 sec)取引のなかった時間帯にはNULLが入っている。続いて
batchdb -uUSERNAMEHERE -pPASSWORDHERE 7312とすると
MariaDB [stockdb]> SELECT * FROM `ohlc_1d` WHERE `sec_code`='7312' ORDER BY `at` DESC LIMIT 10;
+-------------------+----------+------------+------+------+------+-------+
| id | sec_code | at | open | high | low | close |
+-------------------+----------+------------+------+------+------+-------+
| 73120001498662000 | 7312 | 2017-06-29 | 39 | 40 | 32 | 38 |
| 73120001498575600 | 7312 | 2017-06-28 | 35 | 49 | 33 | 35 |
| 73120001498489200 | 7312 | 2017-06-27 | 110 | 110 | 110 | 110 |
| 73120001498402800 | 7312 | 2017-06-26 | NULL | NULL | NULL | NULL |
| 73120001498143600 | 7312 | 2017-06-23 | 113 | 160 | 112 | 160 |
| 73120001498057200 | 7312 | 2017-06-22 | 126 | 135 | 110 | 110 |
| 73120001497970800 | 7312 | 2017-06-21 | 244 | 244 | 244 | 244 |
| 73120001497884400 | 7312 | 2017-06-20 | 324 | 324 | 324 | 324 |
| 73120001497798000 | 7312 | 2017-06-19 | 404 | 404 | 404 | 404 |
| 73120001497538800 | 7312 | 2017-06-16 | NULL | NULL | NULL | NULL |
+-------------------+----------+------------+------+------+------+-------+
10 rows in set (0.00 sec)
MariaDB [stockdb]> SELECT * FROM `extra_1d` WHERE `sec_code`='7312' ORDER BY `at` DESC LIMIT 10;
+-------------------+----------+------------+----------+------------+
| id | sec_code | at | volume | turnover |
+-------------------+----------+------------+----------+------------+
| 73120001498662000 | 7312 | 2017-06-29 | 20337900 | 735335000 |
| 73120001498575600 | 7312 | 2017-06-28 | 59227300 | 2273917600 |
| 73120001498489200 | 7312 | 2017-06-27 | 3459500 | 380545000 |
| 73120001498402800 | 7312 | 2017-06-26 | 0 | 0 |
| 73120001498143600 | 7312 | 2017-06-23 | 32973600 | 4681889400 |
| 73120001498057200 | 7312 | 2017-06-22 | 46751100 | 5721269400 |
| 73120001497970800 | 7312 | 2017-06-21 | 194700 | 47506800 |
| 73120001497884400 | 7312 | 2017-06-20 | 98500 | 31914000 |
| 73120001497798000 | 7312 | 2017-06-19 | 45200 | 18260800 |
| 73120001497538800 | 7312 | 2017-06-16 | 0 | 0 |
+-------------------+----------+------------+----------+------------+
10 rows in set (0.00 sec)1時間足テーブルを集計して日足テーブルに入る。欠損値も含めてダウンロードしてきた日足CSVと一致する。
日付,始値,高値,安値,終値,出来高,売買代金
2017-06-29,39.00,40.00,32.00,38.00,20337900,735335000
2017-06-28,35.00,49.00,33.00,35.00,59227300,2273917600
2017-06-27,110.00,110.00,110.00,110.00,3459500,380545000
2017-06-26,,,,,0,0
2017-06-23,113.00,160.00,112.00,160.00,32973600,4681889400
2017-06-22,126.00,135.00,110.00,110.00,46751100,5721269400
2017-06-21,244.00,244.00,244.00,244.00,194700,47506800
2017-06-20,324.00,324.00,324.00,324.00,98500,31914000
2017-06-19,404.00,404.00,404.00,404.00,45200,18260800
2017-06-16,,,,,0,0Python版も結果は同じ。というかオリジナル。ここまででPythonからHaskellに移植できた。
コメント